FRONTEND
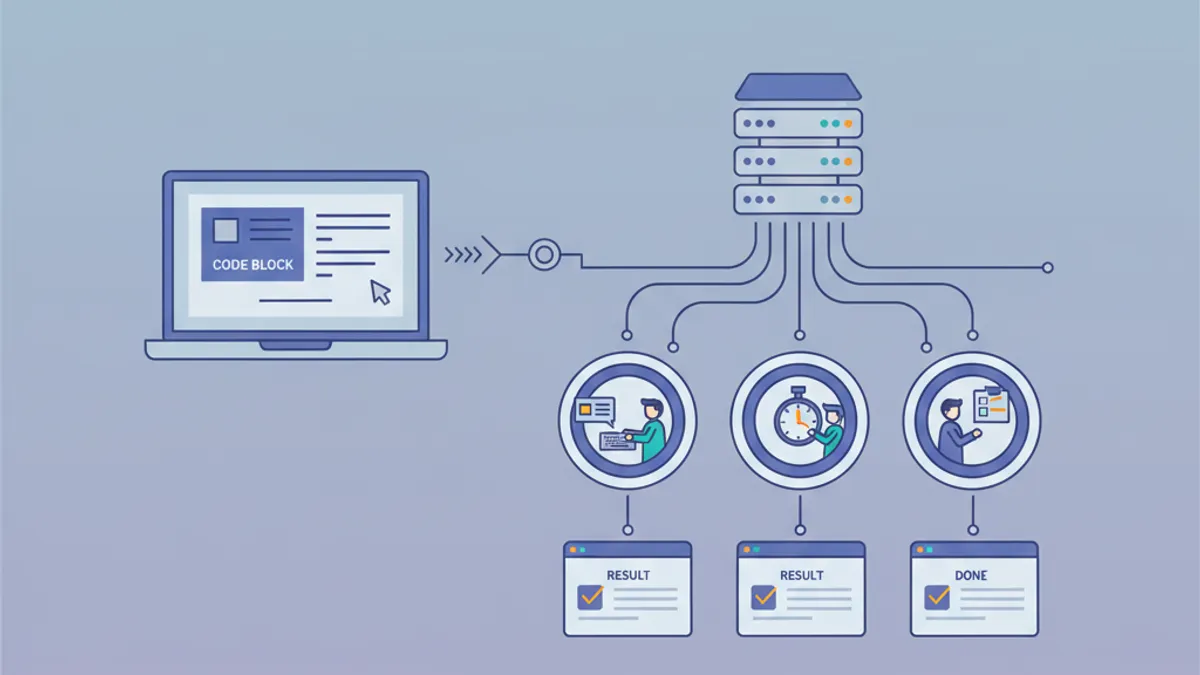
Next.js 16 Cache Components nel 2026: use cache, PPR e Domande da Colloquio per Sviluppatori Senior
Guida completa ai Cache Components di Next.js 16: direttiva use cache, Partial Pre-Rendering, cacheLife, cacheTag, sicurezza con use cache private e domande da colloquio tecnico per il 2026.